Integração de diferentes suportes de dados na estimativa de curto prazo
O problema: dados de qualidade e suporte distintos
Em projetos de mineração, é comum contar simultaneamente com duas ou mais fontes de informação geoquímica que diferem tanto na densidade de amostragem quanto no suporte físico: os furos de sondagem de exploração (DDH ou RC), coletados ao longo de toda a vida do projeto com espaçamentos significativos, e os blast holes (BH), amostrados de forma massiva durante a etapa de produção com malhas muito densas à medida que a lavra avança. Ambas as fontes contêm informação valiosa, mas integrá-las sem o devido cuidado pode introduzir vieses significativos no modelo de recursos.
A questão central é: como aproveitar a alta densidade espacial dos blast holes para melhorar a estimativa de teores a partir dos furos de sondagem, sem comprometer a não-viesabilidade do estimador? A resposta está no cokriging, mas, para aplicá-lo corretamente, é necessário compreender primeiro alguns conceitos estatísticos e geoestatísticos fundamentais.
Relação volume-variância: viés e qualidade
O suporte físico de uma amostra — seu volume — afeta diretamente sua variabilidade estatística. Um blast hole representa um volume de rocha da ordem de dezenas de toneladas, enquanto um DDH composto em intervalos de 2 m representa apenas alguns quilogramas. Pela relação volume-variância, amostras com maior suporte apresentam menor variância e distribuições mais simétricas do que aquelas com suporte reduzido (Donovan, 2015; Minnitt & Deutsch, 2014).
Isso implica que comparar diretamente as distribuições estatísticas de DDH e BH pode levar a conclusões equivocadas sobre o viés entre ambas as fontes. Amostras secundárias de tipo exaustivo — como os blast holes — estão sujeitas às suas próprias fontes de viés, imprecisão e erro. Donovan (2015) identifica três etapas principais nas quais esses problemas podem se originar: o processo de coleta, a análise laboratorial e a preparação dos dados pelo analista.
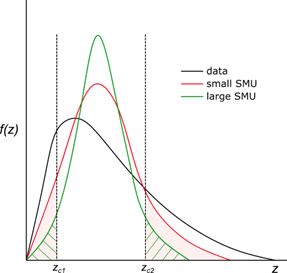
Comparando distribuições de fontes totalmente heterotópicas
Antes de formular qualquer modelo de cokriging, é indispensável avaliar a comparabilidade estatística entre as duas fontes de dados. Para isso, dispõem-se de ferramentas gráficas multivariadas e testes formais que, utilizados em conjunto, permitem detectar vieses sistemáticos e diferenças distribucionais entre ambas as fontes.
A questão central é se duas amostras provêm da mesma distribuição ou, de forma equivalente, se existe uma diferença sistemática na magnitude medida. De forma análoga, pode-se perguntar se uma amostra é consistente com ter sido extraída de uma distribuição conhecida. As distribuições podem ser caracterizadas por sua forma, localização e escala.
Entre as ferramentas disponíveis, os scatter plots permitem visualizar a correlação linear e detectar outliers ou grupos sistemáticos, enquanto os QQ-plots sobrepostos revelam diferenças quantil a quantil entre ambas as distribuições.
Para complementar a análise gráfica, utilizam-se testes de hipótese. O teste de Kolmogorov-Smirnov (KS) avalia se duas amostras provêm da mesma distribuição comparando a diferença máxima entre suas funções de distribuição acumulada; é não paramétrico e robusto frente à não normalidade, embora perca poder nas caudas. O teste de Anderson-Darling é mais sensível a diferenças nas caudas, o que o torna preferível quando, por exemplo, os teores elevados têm maior impacto económico.
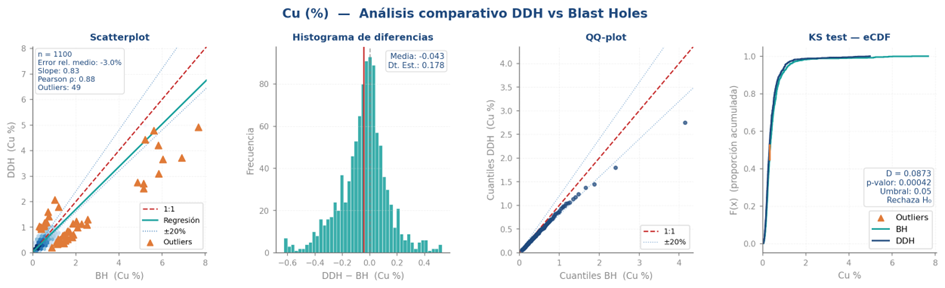
Na prática, nenhum teste isoladamente é conclusivo. A recomendação é combinar os três testes com as visualizações para caracterizar o comportamento conjunto de ambas as fontes de dados. No entanto, cabe perguntar como realizar essa análise quando não existem amostras nas mesmas localizações. A solução habitual é construir pares “gêmeos” por meio de um buffer de distância, selecionando pares de amostras entre ambos os suportes dentro de uma janela de proximidade definida. A Figura 2 ilustra essa análise integrada para uma base de dados hipotética de Cu.
Adicionalmente, el coeficiente de correlación entre pares migrados es un criterio práctico indispensable para definir la estrategia de integración. Siguiendo los criterios de Minnitt y Deutsch (2014) y Donovan (2015), cuando la correlación supera 0,8 ambas fuentes pueden combinarse directamente; entre 0,7 y 0,8 la SCOK generalmente mejora las estimaciones; por debajo de 0,7 su eficiencia se vuelve cuestionable y los resultados deben interpretarse con cautela.
Homotopia e heterotopia
Em geoestatística multivariada, diz-se que duas variáveis são homotópicas quando cada amostra de uma variável possui uma amostra colocada (mesma localização) da outra. Na prática, isso raramente ocorre para informações de diferentes suportes: os DDH e os BH amostram diferentes locais do depósito. Essa condição é denominada heterotopia e tem consequências diretas sobre como será realizado o modelamento espacial e as estimativas de ambas as variáveis. Quando os dados são totalmente heterotópicos, o variograma cruzado experimental entre sondagens e furos não pode ser calculado, pois não existem pares colocados; o variograma cruzado experimental só pode ser calculado com dados homotópicos. A equação do variograma cruzado define que a informação da variável primária “Z” e da variável secundária “Y” deve ser obtida na mesma localização “u”:
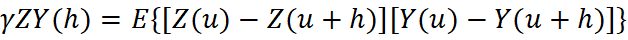
Para lidar com isso, existem algumas alternativas:
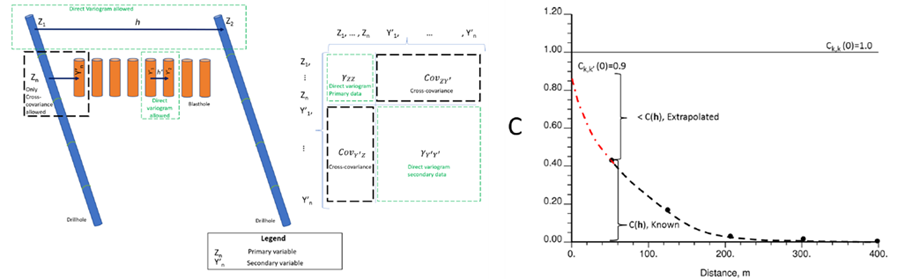
- Extrapolação da covariância e inferência do variograma cruzado: segundo Davila & Deutsch (2022), a covariância cruzada pode ser calculada e extrapolada até a origem na distância:
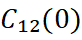
e o variograma cruzado pode ser inferido (Cuba & Deutsch, 2012). Este detalhe tem importância prática: uma correlação cruzada mal extrapolada superestima ou subestima a contribuição da variável secundária ao estimador
- Modelagem Linear de Corregionalização (MLC) direta das covariâncias cruzadas para n distâncias.
- Modelo Intrínseco de Corregionalização (MCI), que é um caso particular do MLC onde o coeficiente de correlação regionalizado é o mesmo para ambas as escalas (a correlação é independente da escala espacial). Nesse caso, os variogramas diretos e cruzados são proporcionais a um mesmo variograma:
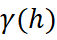
com uma ou mais estruturas:
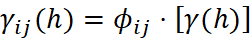
O Modelo Linear de Corregionalização (MLC)
Para qualquer variante de cokriging, os variogramas diretos e o variograma cruzado entre ambos devem ser modelados conjuntamente de forma consistente. Essa exigência é formalizada no Modelo Linear de Corregionalização (MLC), que decompõe cada variograma em N estruturas aninhadas. A condição indispensável é que a matriz de coeficientes:
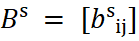
seja semidefinida positiva para cada estrutura N. No caso bivariado, isso se reduz a exigir que:
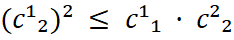
por estrutura. Se essa condição for violada, o sistema de cokriging pode produzir variâncias negativas.
Na prática, o ajuste simultâneo do MLC com três variogramas (diretos e cruzado) é a parte mais trabalhosa do fluxo de trabalho. Ferramentas como Isatis.neo, RMSP e outros softwares de geoestatística permitem ajustar o MLC de forma interativa, com validação automática da condição de semidefinição positiva. Uma alternativa para múltiplas variáveis correlacionadas é a decorrelação por meio de fatores PCA/MAF (Min/Max Autocorrelation Factors)/PPMT, o que permite modelar e simular cada fator de forma independente.
Modelo de Corregionalização Intrínseco (MCI)
O Modelo de Corregionalização Intrínseco (MCI) é um caso particular do Modelo Linear de Corregionalização (MLC), no qual todos os variogramas diretos e cruzados das variáveis analisadas são proporcionais a um mesmo variograma base. Esse variograma pode ser composto por uma ou mais estruturas fundamentais, obedecendo à seguinte propriedade matemática:
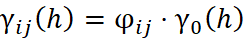
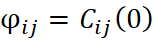
onde:
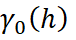
representa um modelo de variograma com patamar unitário;
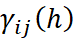
é o variograma direto ou cruzado entre as variáveis i e j;
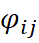
é o coeficiente de proporcionalidade entre os variogramas das diferentes variáveis;
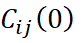
é o valor da matriz de covariância no lag zero.
Nesse contexto, o MCI simplifica a modelagem da dependência espacial entre múltiplas variáveis ao assumir que todas compartilham a mesma estrutura espacial básica, diferenciando-se apenas pelos coeficientes de proporcionalidade. Essa abordagem reduz a complexidade computacional da modelagem geoestatística multivariada, garantindo coerência estatística entre os variogramas diretos e cruzados.
Métodos de estimativa multivariável: cokriging
O cokriging é uma generalização do kriging para múltiplas variáveis que fornece um estimador não viesado de variância mínima. Esse método incorpora a correlação espacial entre variáveis por meio da função de covariância cruzada, permitindo utilizar informação secundária sem a necessidade de amostragem exaustiva. Os dados podem estar localizados nos mesmos pontos da variável primária ou distribuídos em posições espaciais distintas, o que faz do cokriging uma abordagem flexível para modelagem geoestatística multivariada.
O objetivo é melhorar a estimativa da variável primária ao incorporar informação de variáveis secundárias mais densamente amostradas, especialmente quando a variável primária apresenta baixa autocorrelação espacial, enquanto as variáveis secundárias possuem maior continuidade espacial.
Um dos principais benefícios do cokriging é a redução da variância do erro de estimativa, uma vez que aproveita a correlação entre variáveis para melhorar a precisão. Portanto, a variância do erro do cokriging será sempre menor ou igual à do kriging simples, tornando-o mais eficiente para a modelagem geoestatística multivariada.
O estimador do cokriging simples pode ser definido como:
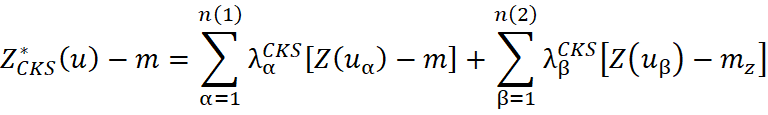
onde:
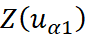
e
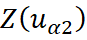
são valores das variáveis aleatórias primária e secundária;
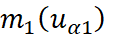
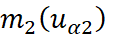
representam as médias das variáveis;
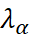
e
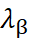
são os pesos do cokriging calculados a partir das covariâncias entre as amostras primárias e secundárias.
Cokriging simples
O cokriging simples assume médias estacionárias e conhecidas para ambas as variáveis. É o mais eficiente em termos de variância, mas sensível a erros nas médias globais. Na prática de mineração, é pouco utilizado, pois raramente se conhecem com precisão as médias de todo o depósito, especialmente nas fases iniciais do projeto.
Cokriging ordinário
No cokriging ordinário, a média é considerada estacionária apenas dentro de uma vizinhança local, em contraste com o cokriging simples, que assume estacionariedade em toda a área de estudo. O estimador do cokriging ordinário para a variável de interesse em um ponto é expresso como:
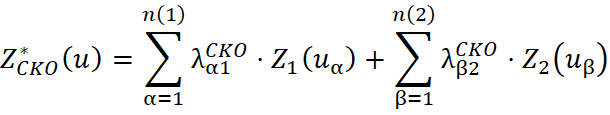
Sob as condições convencionais do cokriging ordinário, a soma dos pesos da variável primária é igual a 1, enquanto a soma dos pesos da variável secundária é igual a 0:
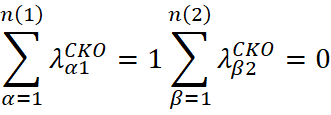
No entanto, na prática, essa restrição sobre os pesos da variável secundária pode gerar pesos negativos ou muito pequenos, o que pode produzir estimativas negativas ou reduzir excessivamente a influência da variável secundária no modelo.
Cokriging ordinário padronizado (SCOK)
O Cokriging Ordinário Padronizado (SCOK), descrito por Goovaerts (1997), é uma metodologia projetada para incorporar dados de qualidade variável, considerando tanto as autocorrelações quanto as correlações cruzadas espaciais entre as variáveis envolvidas. Esse método também reduz o viés introduzido por conjuntos de dados imprecisos, ao operar com resíduos padronizados em vez dos dados originais, garantindo estimativas mais robustas e coerentes.
A SCOK surge como uma alternativa à restrição sobre os pesos da variável secundária no COK, substituindo as duas condições anteriores por uma única restrição: a soma total de todos os pesos deve ser igual a 1:
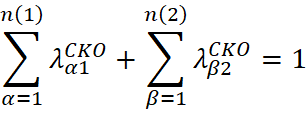
A SCOK tem sido recomendada na indústria de mineração para estimativas de curto e médio prazo quando se integram dados de diferentes qualidades (Davila & Deutsch, 2022). Em casos completamente heterotópicos, é comum modelar diretamente as covariâncias cruzadas por meio do MLC, ou simplificar a estrutura dos variogramas através do MCI.
Cokriging colocalizado
Em alguns casos, não muito frequentes na mineração, a variável secundária é significativamente mais densamente amostrada que a primária, e a informação secundária já se encontra disponível no ponto onde se deseja estimar a variável de interesse. O cokriging colocalizado é uma abordagem que aproveita essa informação para melhorar a estimativa da variável primária. Em bases de dados onde a quantidade de amostras primárias é igual ou superior à de amostras secundárias, a influência de amostras primárias distantes pode comprometer a qualidade da estimativa. Esse problema pode ser resolvido por meio de Modelos de Markov, que propõem utilizar exclusivamente a informação secundária colocalizada. O cokriging colocalizado é mais comum quando a informação secundária é exaustiva, sendo amplamente aplicado em casos onde se integram dados geofísicos ou de sensoriamento remoto na estimativa.
Validação cruzada: K-folds
Uma vez obtidas as estimativas, é necessário avaliar sua qualidade de forma objetiva antes de adotar qualquer metodologia como definitiva. Para isso, utiliza-se a validação cruzada, que consiste em estimar localizações conhecidas a partir do restante dos dados e comparar o valor estimado com o valor real. No contexto da integração de sondagens DDH com blast holes, Donovan (2015) recomenda aplicar essa validação com cuidado, uma vez que o uso de dados secundários com viés no conjunto de treinamento pode comprometer a interpretação dos resultados caso o conjunto de validação não esteja devidamente isolado. Por essa razão, o conjunto de validação deve ser composto exclusivamente por amostras DDH, que representam a fonte de maior confiança e qualidade, enquanto o conjunto de treinamento combina DDH e blast holes de acordo com o método avaliado.
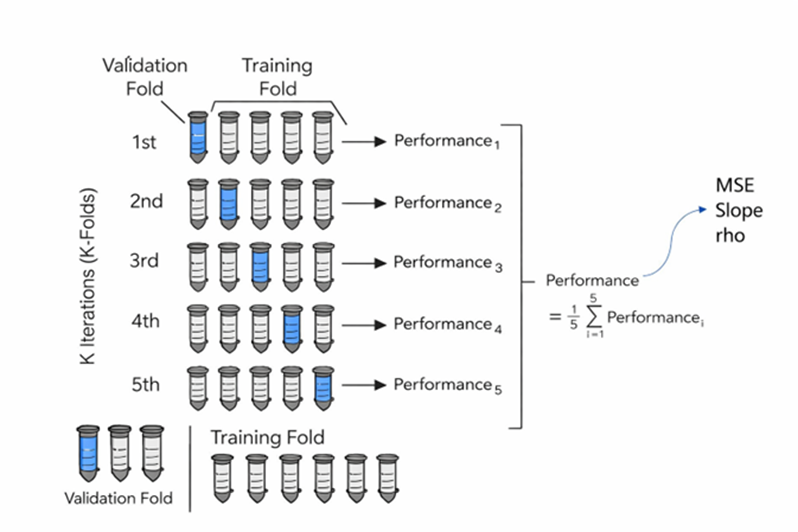
Para robustecer a comparação entre métodos, recomenda-se aplicar uma validação cruzada do tipo K-Folds com K = 5 iterações. Em cada iteração, 20% das sondagens DDH são removidas aleatoriamente e utilizadas como conjunto de validação, enquanto os 80% restantes são combinados com as amostras de blast holes para estimar os valores nas localizações removidas. Esse procedimento é repetido cinco vezes, de modo que a totalidade das sondagens DDH seja utilizada exatamente uma vez como validação, garantindo que cada partição seja independente e espacialmente representativa.
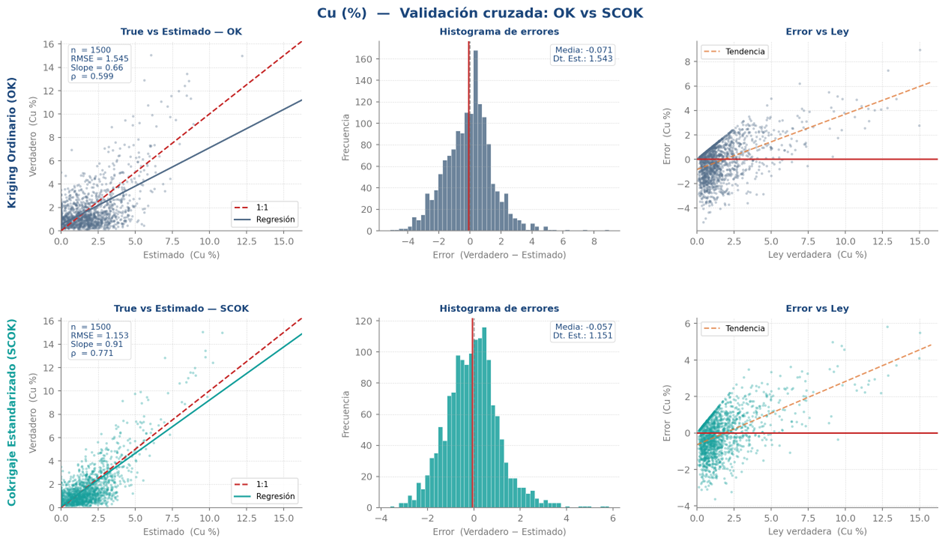
O desempenho final de cada método corresponde à média das métricas calculadas em cada fold, considerando o coeficiente de correlação de Pearson, o erro quadrático médio (MSE) e a inclinação da reta de regressão entre valores estimados e reais. A comparação sistemática desses indicadores entre métodos permite identificar qual técnica reproduz melhor a variável primária com menor viés condicional, orientando assim a seleção de parâmetros e a decisão metodológica final. A Figura 4 ilustra um exemplo de validação cruzada em uma comparação para Cu (%) entre krigagem ordinária (OK) e cokriging ordinário padronizado (SCOK).
Fluxo de trabalho prático e recomendações
A integração de blast holes e sondagens em um modelo geoestatístico robusto requer seguir um fluxo de trabalho estruturado, no qual cada etapa condiciona as decisões da seguinte. A seguir, são descritos os passos críticos do processo recomendado.
Análise comparativa das distribuições: o ponto de partida é a comparação estatística entre as distribuições de DDH e BH por meio de pares de amostras construídos em diferentes distâncias com um buffer de proximidade. Utilizam-se scatter plots, QQ-plots e testes formais como Kolmogorov-Smirnov e Anderson-Darling para quantificar diferenças em forma, localização e escala. É fundamental identificar se existe viés sistemático entre as fontes e avaliar o coeficiente de correlação entre pares migrados, pois isso determina diretamente a viabilidade e eficiência de qualquer estimativa multivariada posterior.
Definição das técnicas a serem comparadas: a partir da análise distribucional e de correlação, é possível estabelecer quais estratégias são aplicáveis. Quando a variável secundária apresenta maior densidade espacial que a primária e a correlação entre ambas é plausível, recomenda-se o uso da SCOK como metodologia principal. No entanto, é recomendável incluir na comparação estimativas alternativas, como krigagem ordinária com dados separados ou com dados combinados sem correção, a fim de dispor de uma linha de base que permita quantificar o benefício real da integração.
Modelagem espacial: esta etapa envolve a construção do modelo de continuidade espacial adequado para cada técnica avaliada. Para a SCOK, é necessário ajustar o Modelo Linear de Corregionalização (MLC) por meio de covariâncias cruzadas, ou sua simplificação por meio do Modelo de Corregionalização Intrínseca (MCI) quando a estrutura espacial de ambas as variáveis é proporcional. Para estimativas com dados combinados, modela-se um único variograma. Em todos os casos, devem ser avaliadas as anisotropias geológicas e a orientação dos domínios estacionários definidos.
Validação cruzada: a comparação entre métodos é realizada por meio de validação cruzada K-Folds (K = 5) sobre os sondagens DDH, que constituem a fonte de referência. Em cada iteração, 20% dos DDH é reservado como conjunto de validação, enquanto os 80% restantes são combinados com os blast holes para a estimativa. As amostras são selecionadas dentro de um buffer espacial que garanta a coexistência de ambas as fontes, evitando vieses espaciais nos resultados. As métricas de desempenho — RMSE, viés médio e correlação de Pearson — são promediadas entre as cinco iterações para obter uma avaliação robusta e independente da partição.
Estimativa em blocos e análise comparativa: uma vez selecionada a metodologia, procede-se à estimativa completa do modelo de blocos com ambas as técnicas para fins de comparação. Validações visuais, swath plots, curvas teor-tonelagem e estatísticas globais permitem avaliar as diferenças em suavização, reprodução da variabilidade e comportamento nas caudas da distribuição. As reconciliações com a produção real, quando disponíveis, constituem a validação mais definitiva.
Seleção do método e integração final: a decisão final deve basear-se no conjunto de evidências acumuladas ao longo do fluxo: coerência estatística entre as fontes, desempenho na validação cruzada, comportamento visual do modelo e consistência com o conhecimento geológico do depósito. O objetivo não é selecionar o método mais sofisticado, mas sim aquele que melhor reproduz a realidade com os dados disponíveis e dentro das condições de estacionariedade do domínio analisado.
Literatura relacionada
A integração de dados de diferente qualidade e suporte na estimativa de recursos minerais tem sido amplamente estudada na literatura geoestatística. Donovan (2015) estabelece que as diferenças estatísticas observadas entre sondagens e blast holes podem ser um artefato do suporte físico e não necessariamente um viés real de amostragem, dado que a relação volume-variância implica que amostras de maior suporte apresentam menor variância e distribuições mais simétricas. Séguret (2015), em um estudo aplicado em um depósito de cobre pórfiro no norte do Chile, demonstra por meio de deconvolução e variograma cruzado que ambas as fontes são coerentes em sua estrutura espacial e podem ser interpretadas como regularizações da mesma realidade, embora cada uma apresente seu próprio erro de medição independente.
Diante desse problema, o cokriging consolida-se como a metodologia mais adequada para integrar fontes de distinta qualidade sem transferir o viés nem a imprecisão para as estimativas. Minnitt e Deutsch (2014) demonstram que o cokriging ordinário padronizado (SCOK), apoiado em um Modelo Linear de Corregionalização (MLC), melhora significativamente a estimativa de reservas recuperáveis em relação à krigagem ordinária, mesmo quando os dados secundários apresentam erros importantes e viés multiplicativo. Araújo e Costa (2015) confirmam esses resultados em cenários de planejamento de curto prazo, mostrando que a SCOK reduz a má classificação de blocos e produz curvas teor-tonelagem mais próximas da distribuição real, enquanto Bassani et al. complementam a análise discutindo as implicações práticas da heterotopia e da diferença de suporte na construção de modelos de recursos integrados.
Referências
Araújo, C.P. & Costa, J.F.C.L. (2015). Integration of different-quality data in short-term mining planning. REM: Revista Escola de Minas, 68(2), 221–227.
Bassani, M.A.A. et al. Integration of data from different supports in mineral resource estimation. [Tesis doctoral]. Universidade Federal do Rio Grande do Sul.
Cuba, M. & Deutsch, C.V. (2012). Inference of the cross variogram. Geostatistics Lessons. Recuperado de geostatisticslessons.com
Davila, F. & Deutsch, C.V. (2022). Standardized ordinary cokriging. Geostatistics Lessons. Recuperado de geostatisticslessons.com
Donovan, P. (2015). Resource Estimation with Multiple Data Types [Tesis de maestría]. University of Alberta.
Goovaerts, P. (1997). Geostatistics for natural resources evaluation. Oxford University Press.
Harding, A. & Deutsch, C.V. (2019). Volume variance relations. Geostatistics Lessons. Recuperado de geostatisticslessons.com
Minnitt, R.C.A. & Deutsch, C.V. (2014). Cokriging for optimal recoverable reserve estimates in mining operations. Journal of the Southern African Institute of Mining and Metallurgy, 114, 189–203.
Séguret, S.A. (2015). Geostatistical comparison between blast and drill holes in a porphyry copper deposit. En Proceedings of the 7th International Conference on Sampling and Blending, Bordeaux, Francia.


