A importância da otimização de hiperparâmetros em modelos de Machine Learning aplicados à mineração
Nos últimos anos, o uso de Machine Learning (ML) na mineração cresceu significativamente, particularmente em aplicações relacionadas à predição de teores, recuperação metalúrgica, classificação geológica e variáveis geometalúrgicas como dureza, consumo energético ou throughput.
No entanto, um dos aspectos mais importantes — e ao mesmo tempo mais subestimados — no desenvolvimento de modelos preditivos corresponde à otimização de hiperparâmetros.
É relativamente comum encontrar estudos onde algoritmos são comparados utilizando apenas parâmetros padrão. Em muitos casos, isso leva a conclusões incorretas sobre o verdadeiro desempenho dos modelos. Um algoritmo aparentemente “ruim” pode superar amplamente outro caso seus hiperparâmetros sejam ajustados corretamente.
Na mineração, onde os datasets costumam ser limitados, caros e espacialmente correlacionados, a correta otimização de hiperparâmetros pode representar a diferença entre um modelo robusto e outro completamente inutilizável operacionalmente.
O objetivo deste artigo é revisar:
- O que são hiperparâmetros
- Por que são importantes
- Como afetam o desempenho de modelos de ML
- Quais metodologias de otimização existem
- Exemplos aplicados a variáveis geometalúrgicas
- Riscos associados ao overfitting
- Recomendações práticas para mineração
O que são hiperparâmetros?
Em termos simples, hiperparâmetros correspondem a configurações externas que controlam o comportamento de um algoritmo de Machine Learning.
Diferentemente dos parâmetros internos do modelo, que são aprendidos automaticamente durante o treinamento, os hiperparâmetros devem ser definidos pelo usuário antes de treinar o modelo.
Por exemplo:
Random Forest
Alguns hiperparâmetros típicos são:
- Número de árvores
- Profundidade máxima
- Número mínimo de amostras
- Quantidade de variáveis avaliadas por nó
XGBoost
Entre os mais relevantes encontram-se:
- Learning rate
- Número de estimadores
- Profundidade
- Regularização
- Subsampling
- Column sampling
Redes neurais
Em redes neurais, os hiperparâmetros incluem:
- Número de camadas
- Quantidade de neurônios
- Learning rate
- Batch size
- Funções de ativação
- Dropout
- Optimizer
Todos esses parâmetros afetam diretamente a capacidade preditiva, a estabilidade, o tempo de treinamento, a generalização e o risco de overfitting.
Por que os hiperparâmetros são tão importantes?
Dois modelos utilizando exatamente o mesmo algoritmo podem apresentar desempenhos completamente distintos dependendo de como seus hiperparâmetros são configurados.
Por exemplo:
- um modelo excessivamente complexo pode memorizar ruído
- um modelo excessivamente simples pode não capturar padrões reais
- um learning rate incorreto pode impedir a convergência
- árvores demais podem aumentar o overfitting
- poucas árvores podem gerar underfitting
Na mineração, isso é especialmente relevante devido a:
- datasets relativamente pequenos
- alta variabilidade espacial
- ruído geológico
- presença de outliers
- domínios complexos
- distribuições altamente assimétricas
Um tuning inadequado pode levar a modelos estatisticamente atrativos durante o treinamento, mas completamente inconsistentes quando aplicados em novas áreas do depósito.
Overfitting e underfitting
Um dos principais objetivos da otimização corresponde a encontrar o equilíbrio correto entre capacidade preditiva e generalização.
Underfitting
O underfitting ocorre quando o modelo é simples demais para capturar a complexidade real dos dados.
Consequências:
- baixo desempenho
- alto viés
- incapacidade de modelar relações não lineares
Exemplos:
- árvores muito pequenas
- poucos estimadores
- regularização excessiva
Overfitting
O overfitting ocorre quando o modelo aprende ruído e particularidades específicas do conjunto de treinamento. Na mineração, isso é particularmente perigoso devido à autocorrelação espacial.
Consequências:
- métricas artificialmente elevadas
- baixo desempenho em validação
- baixa capacidade de extrapolação
Muitas vezes, um modelo parece extremamente preciso simplesmente porque as amostras de treinamento e validação estão espacialmente próximas.
Exemplo de otimização de hiperparâmetros
Neste exemplo, foi desenvolvido um modelo Random Forest Regressor com o objetivo de prever o teor de uma variável de interesse a partir de um conjunto de variáveis geoquímicas.
Com o objetivo de maximizar a capacidade preditiva do modelo, utilizou-se o Optuna, uma biblioteca de otimização de hiperparâmetros baseada em técnicas de busca inteligente que permitem explorar de maneira eficiente o espaço de soluções. Diferentemente de abordagens tradicionais como Grid Search ou Random Search, o Optuna emprega algoritmos de otimização sequencial que aprendem com avaliações prévias para concentrar a busca nas regiões mais promissoras. Durante o processo, cada combinação de hiperparâmetros foi avaliada mediante validação cruzada utilizando o coeficiente de determinação (R²) como métrica objetivo.
A Figura 1 apresenta as curvas de validação obtidas para os principais hiperparâmetros do modelo otimizado. Essas curvas permitem visualizar como o desempenho do Random Forest varia à medida que a complexidade do modelo muda. Em geral, observa-se que níveis muito baixos de complexidade conduzem a situações de underfitting, nas quais o modelo é incapaz de capturar adequadamente a variabilidade do teor, enquanto configurações excessivamente complexas tendem a aumentar o risco de overfitting, reduzindo a capacidade de generalização sobre dados não observados. Os valores selecionados pelo Optuna correspondem à região onde o desempenho em validação atinge seu máximo ou permanece estável.
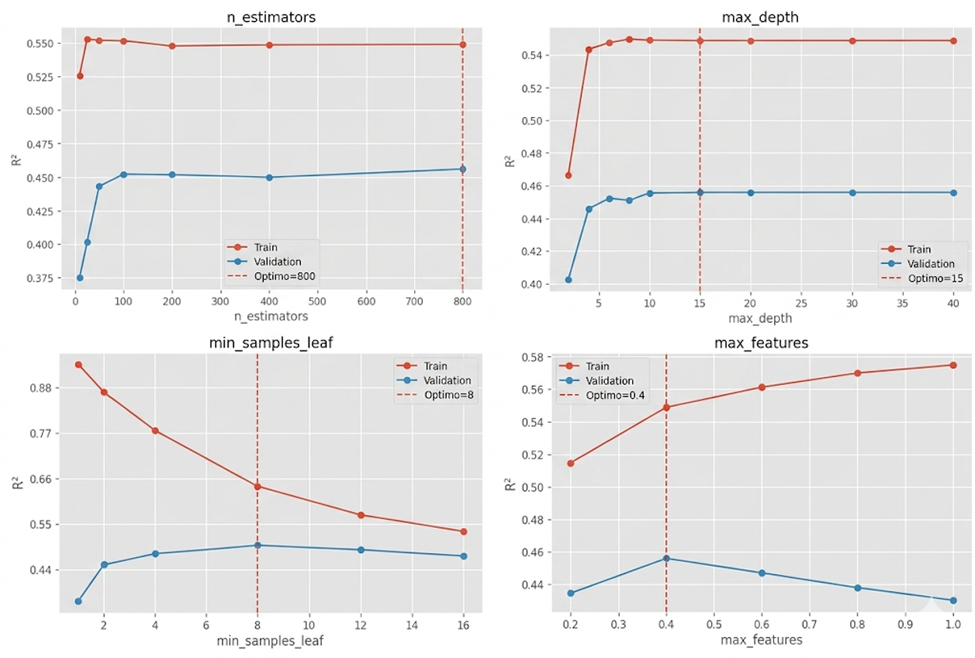
Os resultados obtidos demonstram claramente o benefício da otimização de hiperparâmetros. O modelo base de Random Forest alcançou um R² de 0,454, enquanto o modelo otimizado elevou esse valor para 0,696, o que representa uma melhoria relativa de 53,25% na capacidade explicativa do modelo. Da mesma forma, o RMSE diminuiu 25,35% e o MAE foi reduzido em 16,54%, evidenciando uma melhoria significativa na precisão das predições.
Esses resultados demonstram que a otimização sistemática de hiperparâmetros constitui uma etapa fundamental no desenvolvimento de modelos preditivos para estimativa de teores, permitindo extrair um desempenho consideravelmente superior mesmo a partir de algoritmos já consolidados como o Random Forest.
Reflexão final
A otimização de hiperparâmetros representa um dos aspectos mais importantes do Machine Learning aplicado à mineração. Em muitos casos, as diferenças entre um modelo útil e outro inutilizável não dependem do algoritmo selecionado, mas sim de como ele foi ajustado.
No entanto, a otimização não deve ser entendida apenas como um problema matemático. Na mineração, os modelos precisam respeitar:
- coerência geológica
- continuidade espacial
- domínios
- suporte
- comportamento operacional
O verdadeiro desafio não consiste em construir o modelo com o maior R², mas em desenvolver modelos robustos, interpretáveis e capazes de generalizar corretamente em novas áreas do depósito.
A combinação entre conhecimento geológico, geoestatística e otimização inteligente de Machine Learning representa atualmente uma das áreas mais promissoras para o desenvolvimento de modelos avançados.
Diante disso, surge uma pergunta cada vez mais relevante: quantos modelos considerados “ruins” na mineração realmente falharam por causa do algoritmo… e quantos simplesmente devido a um processo inadequado de otimização?


